TensorFlow Demos
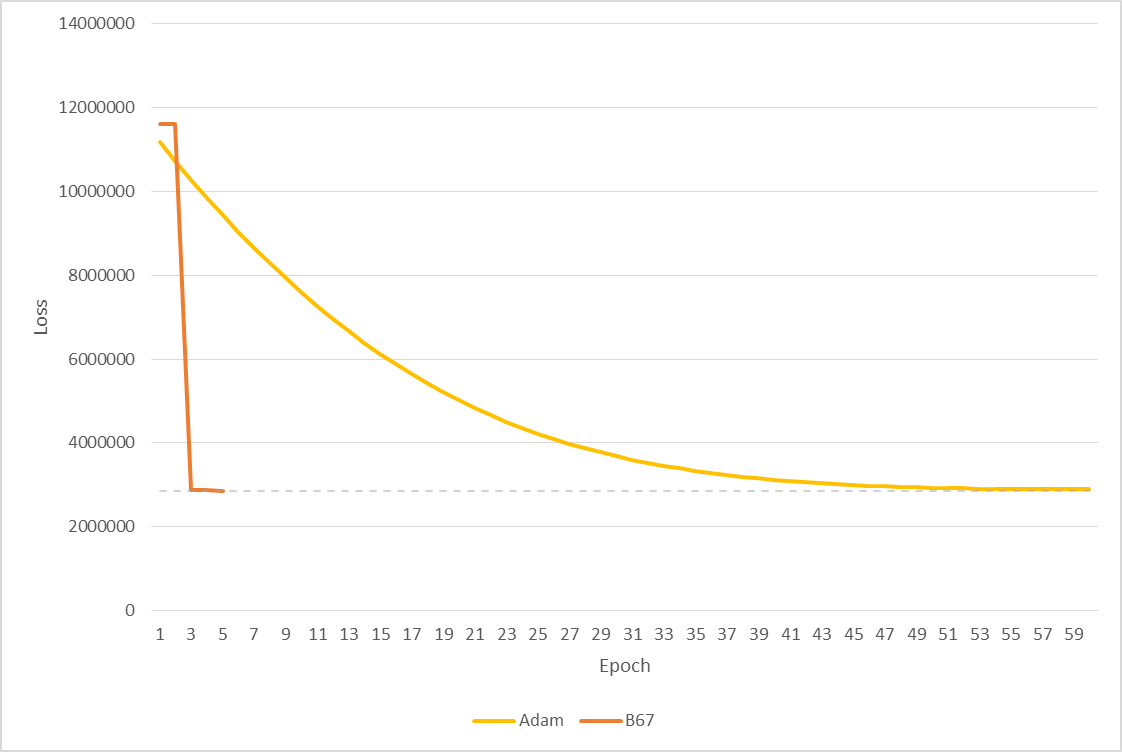
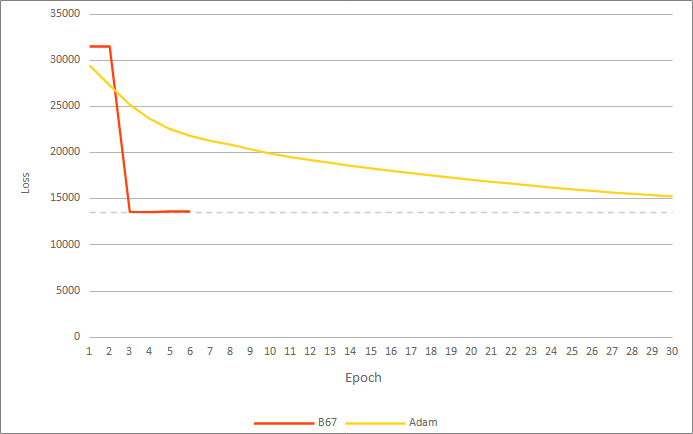
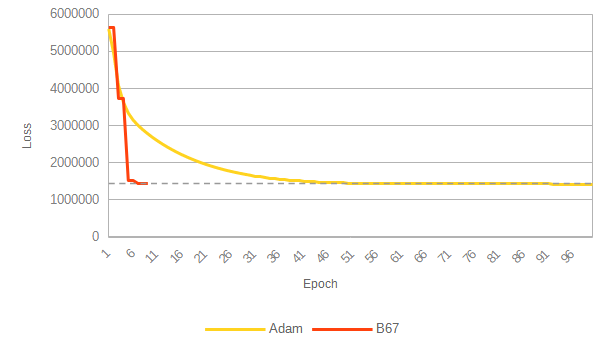
Image Classification with ResNet50
To demonstrate the performance of the B67 algorithm vs. Adam, the ImageNet data set (1.2 million images, 1000 classes) was trained on the ResNet50 neural network using both algorithms.
B67's loss value after a two epochs, was lower than that of Adam algorithm after 58 epochs (see below). And, despite the severe performance limitation incurred by TensorFlow's constraints on our basic demo implementation (see Performance Penalty) this result was achieved in ½ the time it took for Adam to reach a minimum (32.21 hours vs. 64.89 hours). In a production environment this performance penalty does not exist and the time per epoch would be comparable to Adam.
Result Summary
Results are shown below. A plot of loss vs. time is omitted as it is not representative of performance (see Performance Penalty).
Raw Data
Summary logs and screen output are available.
Demonstration Limitations
Performance Penalty
For this demonstration, B67 is implemented as a custom TensorFlow 'op.' TensorFlow does not supply B67's required inputs by default, and we are forced to explicitly recalculate the values that Tensorflow has already performed internally. This recalculation imposes a severe time penatly, and only allows B67 to perform a step once every two epochs. In addition, the custom op is currently implemented for CPU.
As stated above: in a production environment a B67 epoch would take roughly the same amount of time as an Adam (or any of the algorithms packaged in TensorFlow) epoch.
Test Setup
Single node network output
To simplify our calculations at the present time, tested networks are modified to have one output node: for networks with more than one output node, we add an additional Dense layer with a single output.
Randomness Minimized for Performance Comparison
The random seeds for Python, Python's numpy library, and TensorFlow are set to fixed values. In addition, shuffling of data sets is disabled.
Note that there still exist unavoidable variations in floating-point values due to non-deterministic ordering of parallel operations and aggregation of GPU calculations.
Loss function, validation set, batch size
- The loss function used is: .
- The validation set size is 20% of the total input set.
- The batch size is 70 images (largest possible with available memory).
Adam
Adam was run with default parameters.
Software
- Ubuntu 21.04
- Python 3.9.5
- TensorFlow 2.5.0
Hardware
- CPU: Intel Core i7 8-Core 16-Thread, 2.9GHz Base 4.8 GHz Turbo
- GPU: NVIDIA GeForce RTX 3080 10GB
- RAM: 16GB (2x8GB) DDR4 3600MHz
- Hard drive: 1TB 3000MB/s SSD